基于贝叶斯优化的XGBOOST二分类财务造假识别的可解释性分析(修改版)
数据集:
数据来源:国泰安或wind
时间范围:
时间选择距今4-5年,8-12年跨度的上市公司的数据(上市公司平均上市寿命为8-12年,证监会处罚具有滞后性,一般为4-5年。)造假标准为证监会处罚归属于财务造假为准,时间范围从选择的时间起点至今。(最大增加标注准确率)
空间范围:
全部A股上市公司
特征选取
理论基础:
国外:
舞弊三角论,GONE理论,舞弊风险因子理论
国内:黄世忠八因和五维识别模型。
特征:
财务:选取三大财务报表的所有科目,四大指标
非财务:会计师事务所变频率,审计费用,O-Score,Z值,WindESG综合得分,公司市值,成长性,资产价值波动性,风险系数,第一大股东持股比率(%)、管理层持股比例,内部控制是否有效、内部控制是否存在缺陷、是否采取整改措施、是否出具内控评价报告结论、是否披露内控评价报告、会计变更次数(可能为“会计变更次数”)、未完成整改个数、缺陷个数,关联交易占营业收入比、是否增发新股上市,客户集中度,情感语调,cpi,人均可支配收入,GDP增速,PMI,缺失值数量,是否st,以前年度是否造假。
数据分析:
聚类分析(异质性缓解重要)
各行业造假数量分布不同,可按证监会行业先划分后按照业务逻辑进行合并,在合并组内进行KNN聚类处理(可能会出现部分头部或垄断公司)。
线性关系判断:
二分类因变量 + 连续自变量:用逻辑回归检验 logit 尺度的线性关联:
<center>logit(*p*)=ln(*p*/(1−*p*) 其中p为 Y=1 (造假)的概率<center>
|
|
若(beta_1)的 p 值 < 0.05,拒绝 (beta_1=0) 的原假设,认为 X 与 Y 存在统计显著的线性
在模型中加入\(X^2\)项,若其系数显著,说明存在非线性关系(反证原线性假设不成立)。
两个二分类变量则用Phi 系数结合卡方检验判断线性关联强度。
分布分析
概率密度直方图
|
|
缺失值处理
| 缺失比例 | 首选方法 |
|---|---|
| >50% | 删除非关键特征 |
| 20%-50% | 预测模型填充 |
| <20% | 统计量填充+缺失标记 |
异常值处理
分析异常值的原因,如果不符合逻辑删去,如果是偏态分布则log化,压缩数据。
再对正态分布的特征进行Z-Score标准化,非正态则使用修正 Z-Score。
特征构造
相关信息:构造个别特征营业总收入/营业总成本,(应收账款+合同资产)/总资产,利息收入/货币资金,预付账款/总资产,固定资产周转天数,在建工程/总资产
时间趋势信息:构造滞后特征,滑动窗口,拓展窗口,差分特征。
纵向信息:构造平均绝对偏差,最大回撤特征
不平衡数据的处理
| 采样方法 | 适用范围 |
|---|---|
| 欠采样(SMOTE) | 少数类样本分布较均匀,无极端稀疏或孤立点。 |
| 过采样(Random Undersampling) | 多数类样本存在大量冗余 |
| 二者结合(SMOTE + Tomek Links) | 类间边界存在大量 “模糊样本对”,需通过删除边界噪声强化类别区分。 |
| 逻辑构造 | 设定规则,挑选出对应负样本与正样本对应 |
特征筛选
由于XGboost算法计算速度慢,在这里我们先进行初步筛选,删除方差低于阈值,和特征之间高度相关的,在根据内其重要性函数选取一定数量的特征,在进行递归消除来选取特征。XGBoost内嵌评估指标参数并非一定需要,可解释性shap足以胜任,如果筛选后速度仍旧太慢则可改用LightGBM或Catboost。
算法调优
5折交叉验证 将数据按时间顺序划分为连续的5个区块(折),每次训练集为当前折之前的所有数据,测试集为当前折。确保测试集时间点始终晚于训练集。
评估指标:
| PA-AUC:PR曲线是以纵轴为Precision,横轴为Recall,通过改变正负的阀值得到不同的Precision和Recall,构成的曲线,AUC是曲线下方的面积。以此来描述模型的表现。 |
|---|
| 召回率:以实际样本为判断依据,实际为正例的样本中,被预测正确的正例占总实际正例样本的比例。 |
| F2分数:召回率和精确率是一对矛盾的度量,因此需要综合考虑这两个指标,得到一个综合效果最好的模型。但是财务造假对召回率要求较高,普通的二分类评估指标F1并不适合该模型,而F2-Score,在召回率和精确率二者偏向召回率,更适合财务造假模型。 |
阀值优化(寻找最优F2分数)与贝叶斯超参数调优(寻找最优召回率)
对于超参数的选取范围可参考过往论文或XGBoost文档。
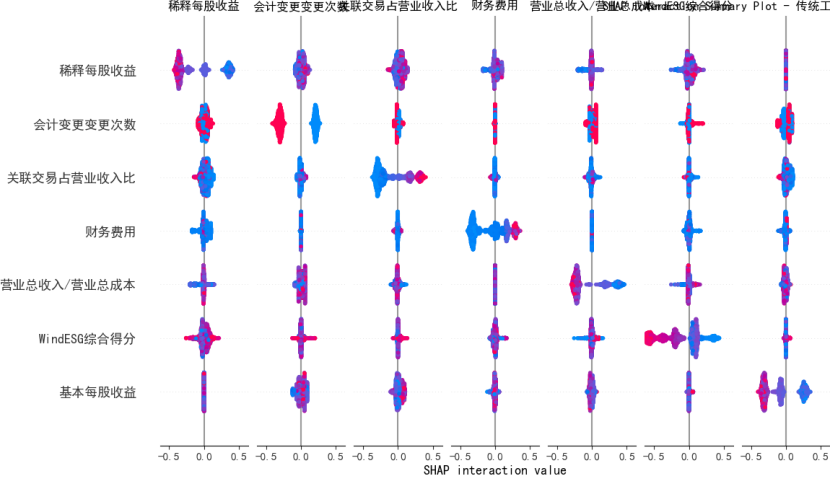
可解释性:
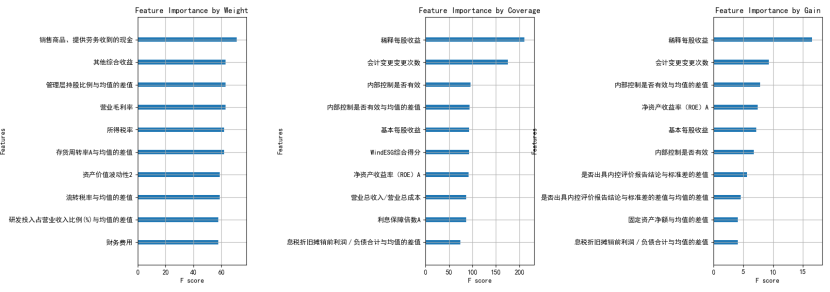
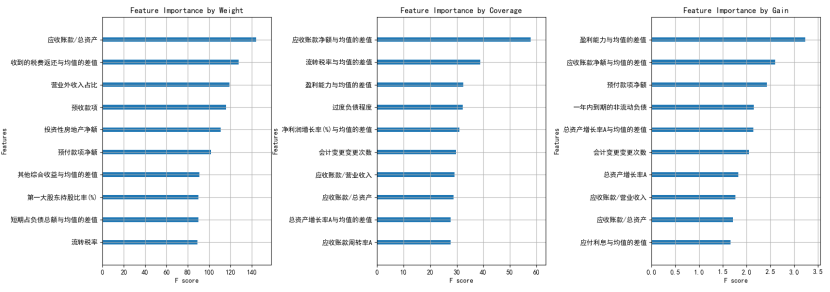
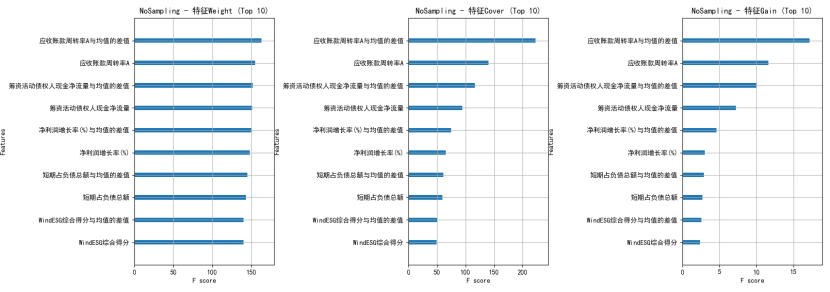
XGboost:用XGBoost内嵌评估指标参数可以增强模型特征可解释性。权重(Weight)、覆盖率(Cover)和增益(Gain)三个评估指标分别反映特征的分裂频次、信息增益及影响样本数量,量化并排序特征的重要性。
shap值:SHAP 即 SHapley Additive exPlanations(夏普利加性解释) ,是可解释人工智能(XAI)领域中一种强大的技术。它基于博弈论中的 Shapley 值,用于解释机器学习模型的输出 。

示例:

相关链接: